
Selinon - A Dynamic Distributed Task Flow Management¶
What is Selinon and why should I use it?¶
Selinon is a tool that gives you a power to define flows, sub-flows of tasks that should be executed in Celery - a distributed task queue. If you want to define very simple flows, Celery offers you workflow primitives that can be used. Unfortunately these workflow primitives are very limited when it comes to extending your workflow, working with multiple dependencies or scheduling tasks based on particular conditions or events.
If you are looking for a workflow solution, take a look at existing solutions, such as Azkaban, Apache Airflow, Apache Nifi, Spotify Luigi and others. The main advantage of using Selinon over these are facts, that you can use it in fully distributed systems and for example let Kubernetes or OpenShift do the workload (and much more, such as recursive flows, sub-flows support, selective task runs, …), define task flows that are not strictly DAG (not strictly directed acyclic graph, but directed graph instead), let system compute which tasks should be run in dependency graph and other features. This all can be accomplished by providing simple and yet intuitive YAML-based configuration files.
Even if you do not plan to run Selinon in a distributed environment, you could still find Selinon useful. Selinon offers you a CLI executor that, based on your YAML configuration, executes tasks based on their dependencies and conditions.
Is there available a demo?¶
You can take a look at Selinon demo so you can see how Selinon works without deep diving into code and configuration. Just run:
docker-compose up
What do I need?¶
In order to use Selinon, you need:
- a basic knowledge of Python3 (yes, there is no support for Python2!)
- YAML markup language (very intuitive and easy to learn)
- a basic knowledge of Celery 4 (older versions are not supported) and its configuration
- a message broker that is supported by Celery if you plan to run Selinon in a distributed environment
- vegetable appetite ;-)
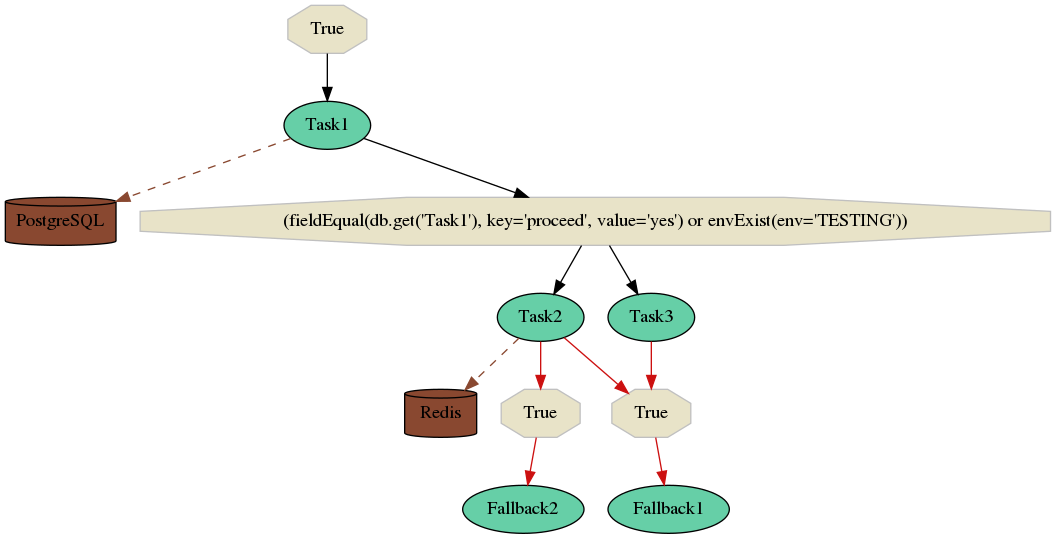
How does it work? - a high level overview¶
The key idea lies in Dispatcher - there is created a Dispatcher task for each flow. Dispatcher takes care of starting new tasks and sub-flows, checking their results and scheduling new tasks based on your configuration. Dispatcher is transparently scheduled and periodically samples flow status and makes decissions what tasks and flows should be scheduled.
The only thing that needs to be provided by you is a YAML configuration file that specifies dependencies of your tasks and where results of tasks should be stored (if you want persistence). This configuration file is parsed by Selinon and automatically transformed to a Python3 code which is then used by Selinon.
See also¶
- Selinon on GitHub
- Selinon organization with various repos on GitHub
- Selinon demo on GitHub
- Celery configuration
Indices and tables¶
Documentation was automatically generated on 2023-01-27 at 16:07.